12 KiB
1. СОЦИАЛЬНЫЕ СЕТИ И ИСПОЛЬЗОВАНИЕ ИХ ДАННЫХ
В настоящее время используется большое множество социальных сетей, самыми популярными из них являются: Facebook, Twitter, LinkedIn, Instagram, ВКонтакте и т.д. Наибольший интерес при этом представляют следующие данные: контент и связи в социальных сетях.
Контент социальных сетей
В части контента имеет место следующее. Данные социальных сетей в основном являются неструктурированными и представляют собой различную сущность. Социальные сети можно условно классифицировать по типу данных следующим образом:
- содержащие преимущественно текстовые данные – Twitter, Telegram, LiveJournal и т.д.;
- содержащие преимущественно изображения – Instagram, Snapchat и т.д.;
- содержащие преимущественно видео – YouTube, Vimeo и т.д.;
- содержащие данные смешанного типа видео – FaceBook, ВКонтакте и т.д.
Для анализа различных типов данных существуют различные подходы и методы. Зачастую неструктурированные «сырые» данные подлежат предварительной обработке. Схема работы с данными социальных сетей в обобщенном виде представлена на рис. 2.

Рис. 2. Схема обработки неструктурированных данных
Первый этап работы с данными социальных сетей обусловлен, прежде всего, наличием необходимого инструментария, а также возможностью предоставления сбора (открытого API) самой социальной сетью. Сбор может осуществляться как уже размещенных в социальных сетях данных, так и в режиме on-line. При этом еще на этапе сбора можно ставить определенные фильтры, к примеру, собрать лишь те сообщения, в которых присутствует то или иное слово или хештег.
Такие компании как IBM, Cloudera, Apache Software Foundation, Hortonworks и другие предоставляют различные платформы для сбора и обработки данных.
Объём собранных (собираемых) данных может быть в достаточной степени велик. Более того, потоковые данные, полученные из социальных сетей обычно содержат в себе множество служебной информации. При этом для дальнейшего анализа бывают важны лишь те данные, которые представляют интерес, поэтому необходимо отделить служебную информацию от нужной. В описанных выше платформах, как правило, используется технология, основанная на модели распределенных вычислений MapReduce. С помощью этой технологии производится структуризация путем компоновки и исключения служебных и не представляющих практический интерес данных. В подходе, основанном на данной модели, производятся вычисления некоторых наборов распределенных задач с использованием большого количества компьютеров (называемых «нодами»), образующих кластер. Работа MapReduce состоит из двух шагов: Map и Reduce. На Map-шаге происходит предварительная обработка входных данных. Для этого один из компьютеров (называемый главным узлом — master node) получает входные данные задачи, разделяет их на части и передает другим компьютерам (рабочим узлам — worker node) для предварительной обработки. Название данный шаг получил от одноименной функции высшего порядка.
На Reduce-шаге происходит свёртка предварительно обработанных данных. Главный узел получает ответы от рабочих узлов и на их основе формирует результат – решение задачи, которая изначально формулировалась. Пример работы технологии MapReduce показан на рис. 3.
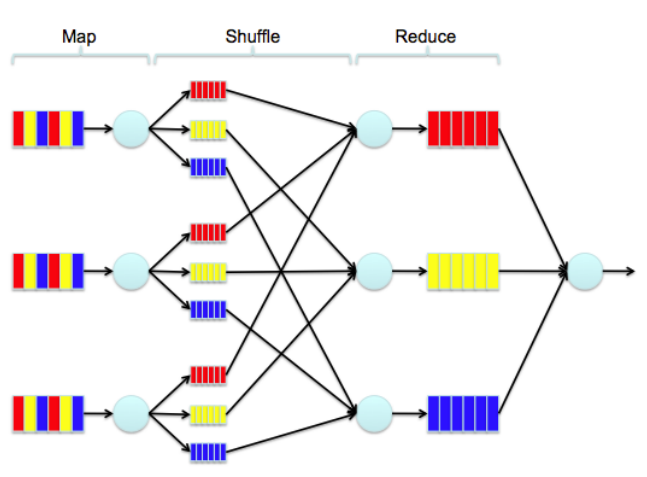
Рис. 3. Алгоритм работы технологии MapReduce
Преимущество MapReduce заключается в том, что она позволяет распределённо производить операции предварительной обработки и свёртки. Операции предварительной обработки работают независимо друг от друга и могут производиться параллельно (хотя на практике это ограничено источником входных данных и/или количеством используемых процессоров). Аналогично множество рабочих узлов могут осуществлять свёртку – для этого необходимо, чтобы все результаты предварительной обработки с одним конкретным значением ключа обрабатывались одним рабочим узлом в один момент времени. Хотя этот процесс может быть менее эффективным по сравнению с более последовательными алгоритмами, технология MapReduce может быть применена к большим объёмам данных, которые могут обрабатываться большим количеством серверов. Так, MapReduce может быть использована для сортировки петабайта данных, что займёт всего лишь несколько часов. Параллелизм также даёт некоторые возможности восстановления после частичных сбоев серверов: если в рабочем узле, производящем операцию предварительной обработки или свёртки, возникает сбой, то его работа может быть передана другому рабочему узлу (при условии, что входные данные для проводимой операции доступны).
Обработанные и структурированные данные анализируются в соответствие с их типом. Отдельные примеры подобной аналитики представлены в следующих разделах данного учебного пособия.
Связи в социальных сетях
Не менее важными, чем контент, данными являются связи в социальных сетях. Они могут характеризовать знакомство, влияние, а также принадлежность тому или иному сообществу. Исследуя связи в социальных сетях можно решать задачи определения предпочтений и интересов пользователей. Это может, в том числе, использоваться в работе ряда рекомендательных систем.
Социальные сети, в части связей, могут быть обычно представлены в виде графов (рис. 4). Это обусловлено тем, что аккаунты в социальных сетях отождествляются с вершинами в графе, а связи – с рёбрами, при этом в зависимости от вида связи (дружба, либо подписка) граф может быть, как неориентированным, так и ориентированным.
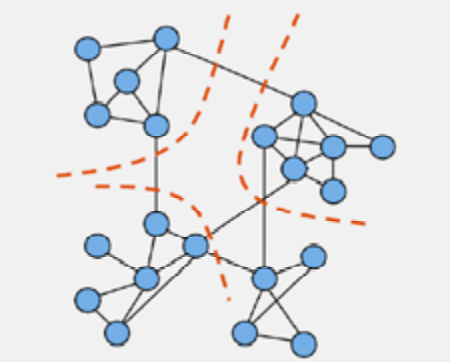
Рис. 4. Фрагмент социальной сети, описаный графом
С помощью инструментов теории графов можно решать различные задачи, такие как, например:
- определение сообществ;
- принадлежность к конкретному сообществу;
- относительная роль узлов и рёбер в графе и т.д.
Граф, описывающий социальную сеть или ее фрагмент, ввиду значительного количества профилей и связей между ними, является графом большой размерности (рис. 5). При этом актуальной задачей становится визуализация такого графа, возможная сегментация, либо кластеризация, позволяющая, в том числе уменьшить, его размерность для более удобного восприятия, но без потерь значимой информации.
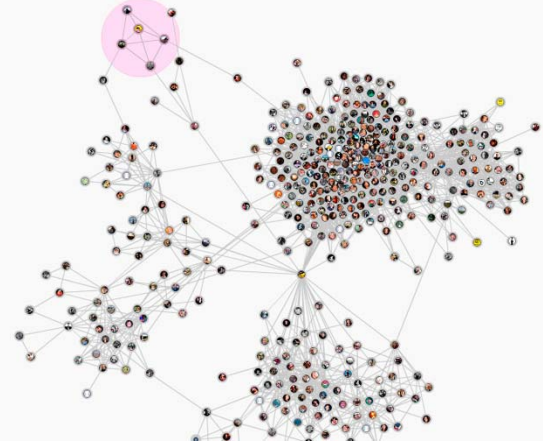
Рис. 5. Фрагмент социальной сети, описаный графом большой размерности
Кластеризация графа большой размерности также может быть использована для отыскания сетевых сообществ, с возможной дальнейшей их классификацией.