15 KiB
Лабораторная работа 3. «Кластеризация изображений»
В рамках данной лабораторной работы будет производится кластеризация собранных из социальной сети изображений.
1. Скачивание фотографий из социальной сети
При выполнении данной лабораторной работы следует использовать пакет VK (не VK_api). Установим данный пакет с помощью следующей команды.
$ pip install vk
Необходимо создать приложение VK для того, чтобы получить доступ к данным. Для этого перейдем на страницу разработчиков VK и в разделе «Мои приложения» создадим новое приложение. Для дальнейшей работы нам потребуется ID приложения и Защищённый ключ. Войдем в VK.
from urllib.request import urlretrieve
import vk, os, time, math
# Авторизация
login = ''
password = ''
vk_id = 'ID_ВАШЕГО_ПРИЛОЖЕНИЯ'
session = vk.AuthSession(app_id=vk_id,
user_login=login, user_password=password)
vkapi = vk.API(session)
Для удобства, входными данными можно указать ссылки на альбомы. Только целиком url не подойдёт, понадобится id хозяина альбома (группы или человека) и id самого альбома, которые и можно достать из ссылки. К примеру, в https://vk.com/album-54530371_212428070 id владельца (в данном случае сообщества) это -54530371, а id альбома – 212428070. Следует обратить внимание, если загружать из альбома сообщества, то «-» (дефис) перед id владельца обязателен.
Получаем на вход ссылку на альбом, затем разбираем её и раскладываем по переменным album_id и owner_id соответствующие id.
Далее нужно получить количество фото, а также инициализировать переменные для статистики.
#url = input("Введите url альбома: ")
url = "https://vk.com/album223007487_199949846"
# Разбираем ссылку
album_id = url.split('/')[-1].split('_')[1]
owner_id = url.split('/')[-1].split('_')[0].replace('album', '')
photos_count = vkapi.photos.getAlbums(
owner_id=owner_id,
album_ids=album_id)[0][‘size’]
counter = 0 # текущий счетчик
prog = 0 # процент загруженных
breaked = 0 # не загружено из-за ошибки
time_now = time.time() # время старта
Проблема при загрузке большого количества фотографий в том, что за один запрос нельзя забрать больше 1000 штук, в то время как в альбоме их может быть десяток тысяч.
Процесс загрузки описывается следующим образом.
#Создадим каталоги
if not os.path.exists('saved'):
os.mkdir('saved')
photo_folder = 'saved/album{0}_{1}'.format(owner_id, album_id)
if not os.path.exists(photo_folder):
os.mkdir(photo_folder)
# Подсчитаем, сколько раз нужно получать список фото, так как число получится не целое - округляем в большую сторону
for j in range(math.ceil(photos_count / 1000)):
photos = vkapi.photos.get(
owner_id=owner_id,
album_id=album_id,
count=1000,
offset=j*1000,
v=5.95)['items']
# Получаем список фото
for photo in photos:
counter += 1
sizes = photo['sizes']
s = photo['sizes'][0]
value_x = 0
value_y = 0
# выбираем самый большой размер
for size in sizes:
if value_x < size['width']:
value_x = size['width']
s = size
if value_y < size['height']:
value_y = size['height']
s = size
print(s['url'])
# Получаем адрес изображения
url_ = s['url']
print('Загружаю фото № {} из {}. Прогресс: {}'.format(counter, photos_count, prog))
prog = round(100/photos_count*counter, 2)
try:
# Загружаем и сохраняем файл
urlretrieve(url_, photo_folder + "/" + os.path.split(url_)[1])
except Exception:
print('Произошла ошибка, файл пропущен.')
breaked += 1
continue
time_for_dw = time.time() - time_now
print("\nВ очереди было {} файлов. Из них удачно загружено {} файлов, {} не удалось загрузить.")
2. Кластеризация цветов на изображении
Кластерный анализ (англ. Data clustering) – задача разбиения заданной выборки объектов (ситуаций) на непересекающиеся подмножества, называемые кластерами, так, чтобы каждый кластер состоял из схожих объектов, а объекты разных кластеров существенно отличались.
В рамках данной лабораторной работы будет решаться задача кластерного анализа изображений, собранных из задания 1.
Для начала попробуем обработать одну картинку, а именно, решим задачу определения доминирующих цветов.
Американский веб-разработчик Чарльз Лейфер (Charles Leifer) использовал метод k-средних для кластеризации цветов на изображении. Идея метода при кластеризации любых данных заключается в том, чтобы минимизировать суммарное квадратичное отклонение точек кластеров от центров этих кластеров. На первом этапе выбираются случайным образом начальные точки (центры масс) и вычисляется принадлежность каждого элемента к тому или иному центру. Затем на каждой итерации выполнения алгоритма происходит перевычисление центров масс – до тех пор, пока алгоритм не сходится.
В применении к изображениям каждый пиксель позиционируется в трёхмерном пространстве RGB, где вычисляется расстояние до центров масс. Для оптимизации картинки уменьшаются до 200х200 с помощью библиотеки PIL. Она же используется для извлечения значений RGB.
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import cv2
#read image
img = cv2.imread('colors.jpg')
#convert from BGR to RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
#get rgb values from image to 1D array
r, g, b = cv2.split(img)
r = r.flatten()
g = g.flatten()
b = b.flatten()
#plotting
fig = plt.figure()
ax = Axes3D(fig)
ax.scatter(r, g, b)
plt.show()
Данный код обрабатывает изображение и определяет пять самых доминирующих цветов на изображении.
В результате исполнения кода получим график примерно такого вида (рис. 31). На нем можно увидеть распределение пикселей в трехмерном пространстве. Здесь также легко выделить пять доминирующих цветов (рис. 32).
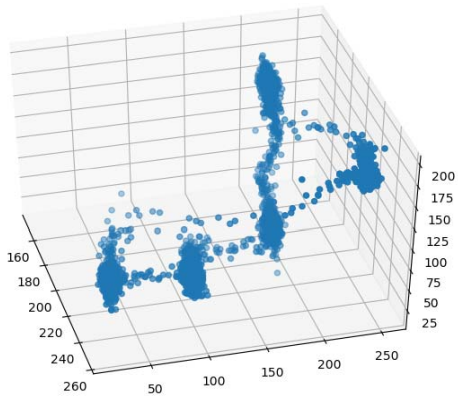
Рис. 31. Распределение пикселей в трехмерном пространстве
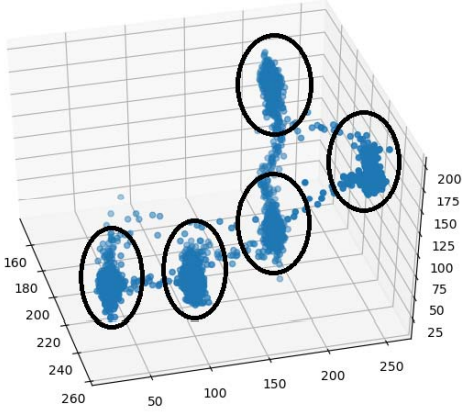
Рис. 32. Выделение доминирующих цветов
Несколько преобразим имеющийся код.
import cv2
from sklearn.cluster import KMeans
class DominantColors:
CLUSTERS = None
IMAGE = None
COLORS = None
LABELS = None
def __init__(self, image, clusters=3):
self.CLUSTERS = clusters
self.IMAGE = image
def dominantColors(self):
#read image
img = cv2.imread(self.IMAGE)
#convert to rgb from bgr
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
#reshaping to a list of pixels
img = img.reshape((img.shape[0] *img.shape[1], 3))
#save image after operations
self.IMAGE = img
#using k-means to cluster pixels
kmeans = KMeans(n_clusters = self.CLUSTERS)
kmeans.fit(img)
#the cluster centers are our dominant colors.
self.COLORS = kmeans.cluster_centers_
#save labels
self.LABELS = kmeans.labels_
#returning after converting to integer from float
return self.COLORS.astype(int)
img = 'colors.jpg'
clusters = 5
dc = DominantColors(img, clusters)
colors = dc.dominantColors()
print(colors)
На выходе мы получим пять векторов, где будут закодированы 5 основных цветов в формате RGB.
Далее построим гистограмму использования этих пяти основных цветов. Для этого добавим функцию plotHistogramm() в класс DominantColors.
def plotHistogram(self):
#labels form 0 to no. of clusters
numLabels = np.arange(0, self.CLUSTERS+1)
#create frequency count tables
(hist, _) = np.histogram(self.LABELS, bins= numLabels)
hist = hist.astype("float")
hist /= hist.sum()
#appending frequencies to cluster centers
colors = self.COLORS
#descending order sorting as per frequency count
colors = colors[(-hist).argsort()]
hist = hist[(-hist).argsort()]
#creating empty chart
chart = np.zeros((50, 500, 3), np.uint8)
start = 0
#creating color rectangles
for i in range(self.CLUSTERS):
end = start + hist[i] * 500
#getting rgb values
r = colors[i][0]
g = colors[i][1]
b = colors[i][2]
#using cv2.rectangle to plot colors
cv2.rectangle(
chart,
(int(start), 0),
(int(end), 50),
(r,g,b),
-1)
start = end
#display chart
plt.figure()
plt.axis("off")
plt.imshow(chart)
plt.show()
Далее вызовем эту функцию.
dc.plotHistogram()
На выходе получим пропорциональное отображение использования доминирующих цветов на изображении. Пример отображения представлен на рис. 33.

Рис. 33. Отображение использования доминирующих цветов на изображении
3. Кластеризация изображении на основе доминирующих цветов
Теперь, когда получена характеристика одного изображения, у нас есть инструмент, с помощью которого можно произвести кластеризацию множества изображений на основе их доминирующих цветов. Для этого необходимо обработать каждое изображение в папке, получить его уникальную цветовую характеристику и сравнить ее с другими изображениями. Поэтому немного модифицируем имеющийся код:
- добавим глобальную переменную, в которой будем хранить цветовые характеристики каждой картинки;
- за место конкретной картинки будем указывать директорию и будем итерационно обрабатывать каждую картинку.
directory = '<ПУТЬ К ДИРЕКТОРИИ>'
for filename in os.listdir(directory):
data_iter = []
filenames.append(filename)
img = str(directory) + '\\' + filename
#print (img)
clusters = 2
dc = DominantColors(img, clusters)
colors = dc.dominantColors()
for i in colors:
for j in i:
data_iter.append(j)
data.append(data_iter)
print(colors)
Преобразуем список в массив данных и добавим код метода главных компонент для того, чтобы понизить размерность вектора характеристик с 15 до 3.
np_data = np.asarray(data, dtype=np.float32)
import numpy as np
from sklearn.decomposition import PCA
pca = PCA(n_components = 3)
XPCAreduced = pca.fit_transform(np_data)
print(XPCAreduced)
print(filenames)
Далее представим точки изображения на плоскости, где координатами будут элементы вектора характеристик.
xs, ys, zs = np_data[:, 0], np_data[:, 1], np_data[:,2]
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(xs, ys, zs)
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_zlabel('Z')
plt.show()